AI-Powered • Local Processing
Intelligent Document Analysis Platform
A personal app to upload PDFs and interact with them using AI summarization and Q&A, built with LangChain, Ollama Llama 3.2/Qwen3:8B, and FAISS DB. Extracts relevant formulas, images, and graphs pertaining to your queries for comprehensive document analysis.
Live demonstration of document analysis and AI-powered Q&A capabilities
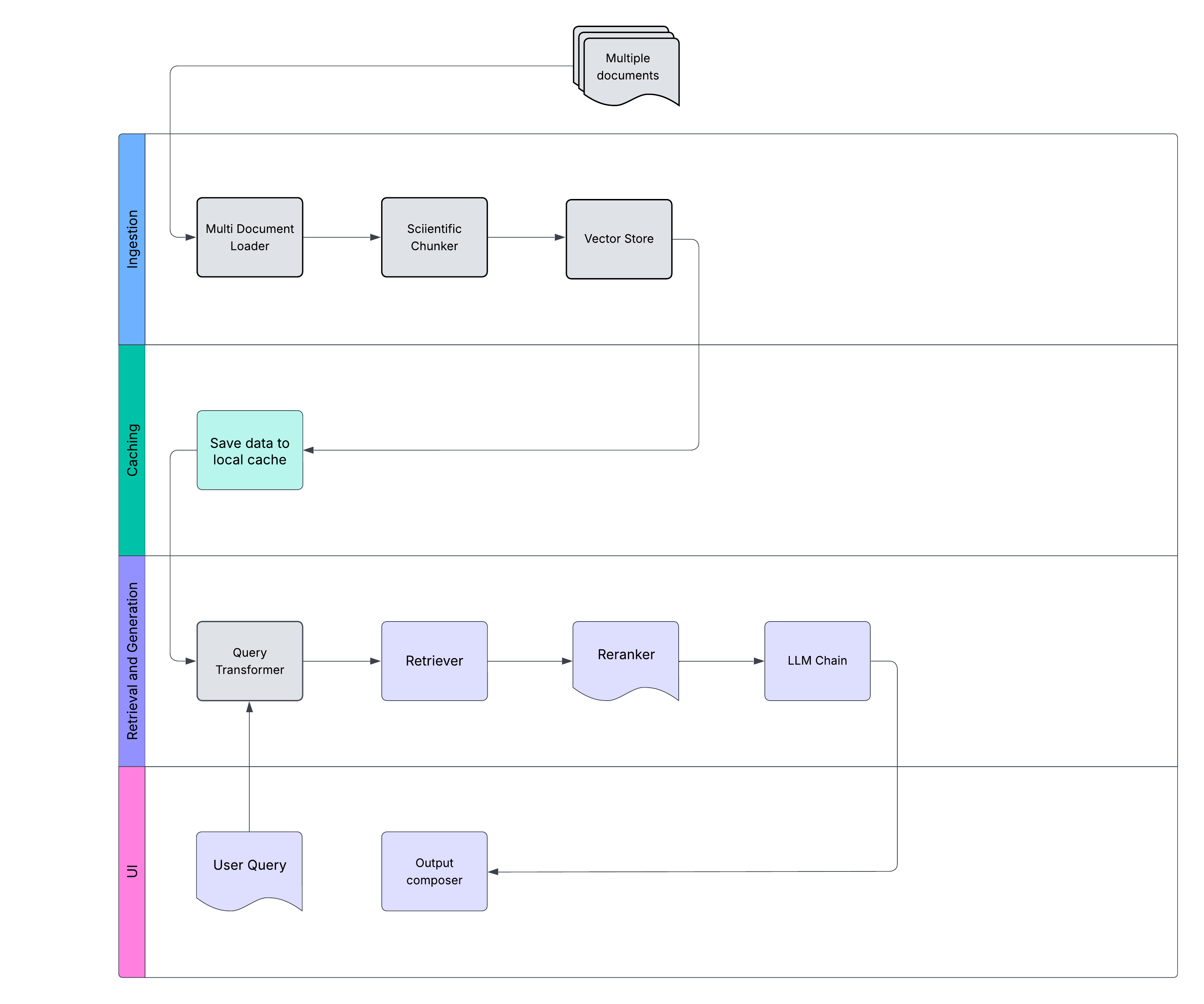
System Architecture Flow
Complete workflow from document input to AI-powered insights